TeamCognito.
GENERATIVE ADVERSARIAL NETWORK (GANs)
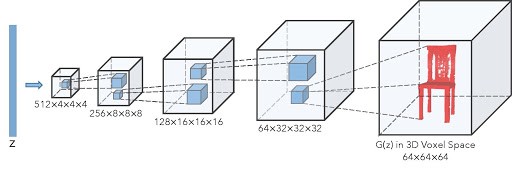
Generative adversarial networks (GANs) are algorithmic architectures that use two neural networks, pitting one against the other in order to generate new, synthetic instances of data that can pass for real data. GANs were introduced in a paper by Ian Goodfellow and other researchers at the University of Montreal, including Yoshua Bengio, in 2014. They are used widely in image generation, video generation and voice generation.
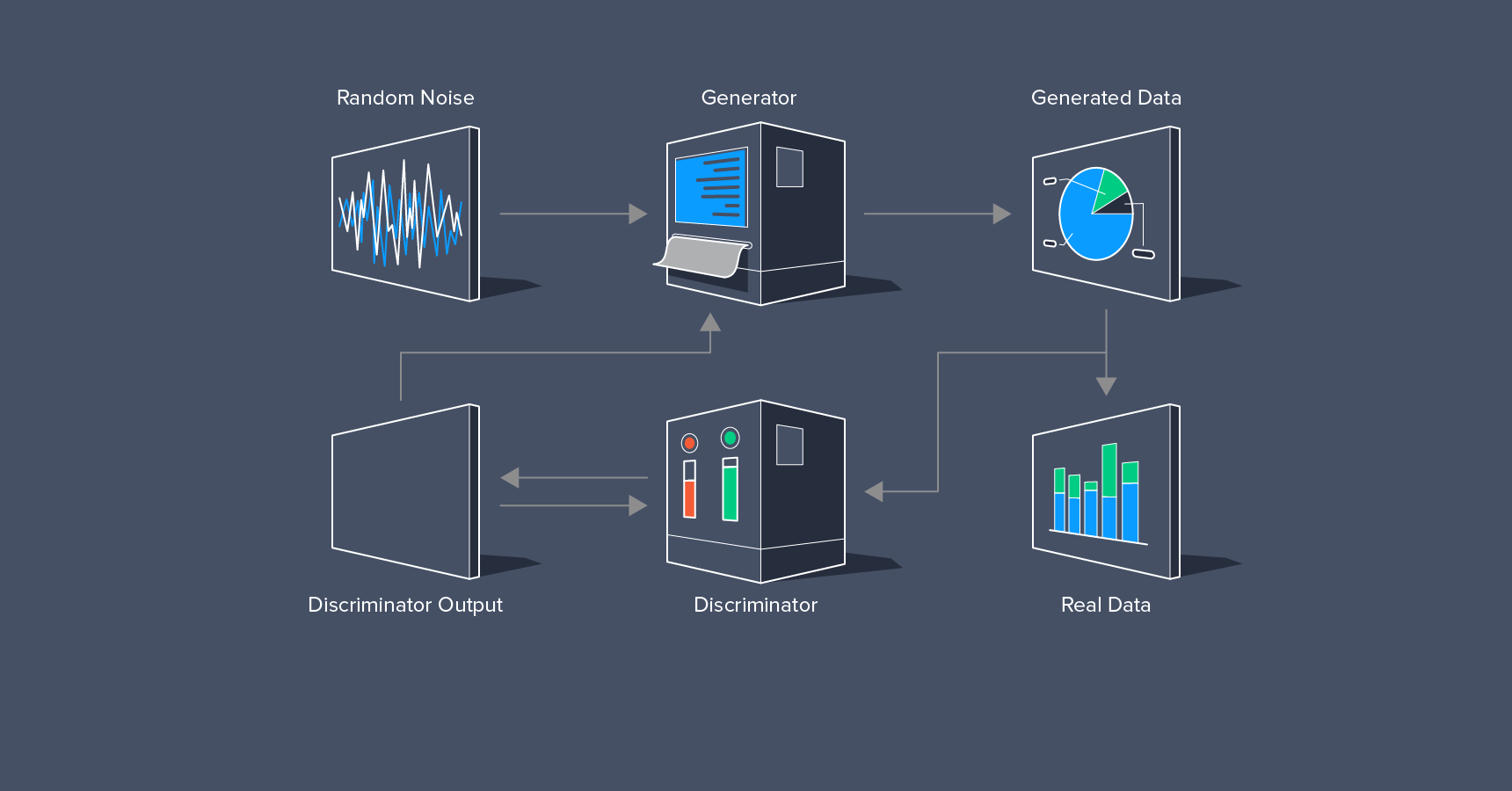
GANs consist of two parts: generators and discriminators. The generator model produces synthetic examples (e.g., images) from random noise sampled using a distribution, which along with real examples from a training data set are fed to the discriminator, which attempts to distinguish between the two. Both the generator and discriminator improve in their respective abilities until the discriminator is unable to tell the real examples from the synthesised examples with better than the 50% accuracy expected of chance. The goal of the generator is to generate passable hand-written digits: to lie without being caught. The goal of the discriminator is to identify images coming from the generator as fake.
Here are the steps a GAN takes:
- The generator takes in random numbers and returns an image.
- This generated image is fed into the discriminator alongside a stream of images taken from the actual, ground-truth dataset.
- The discriminator takes in both real and fake images and returns probabilities, a number between 0 and 1, with 1 representing a prediction of authenticity and 0 representing fake.